Add CSV Data to Your Extracted Records
You may find yourself wanting to add data stored offline to the web-content you are extracting. With the Crawler, you can do this in just three steps:
- Upload your data to Google Sheets.
- Publish your spreadsheet online as a CSV.
- Link the published CSV in your crawler’s configuration.
Prerequisites
Ensure that your spreadsheet’s format is compatible with the crawler:
- It must contain headers.
- One of the headers must be
url(theurlcolumn should contain all URLs that you want to add external data to).
Upload your data to Google Sheets
The first step is to upload your data to Google Sheets. This is highly dependent on the format and storage of your data, but the process should be relatively straightforward. If you want to follow along, this example uses the following google sheet.
Publish your spreadsheet online
1. Click on the Share button of your Google spreadsheet.
 2. Click on Advanced.
2. Click on Advanced.
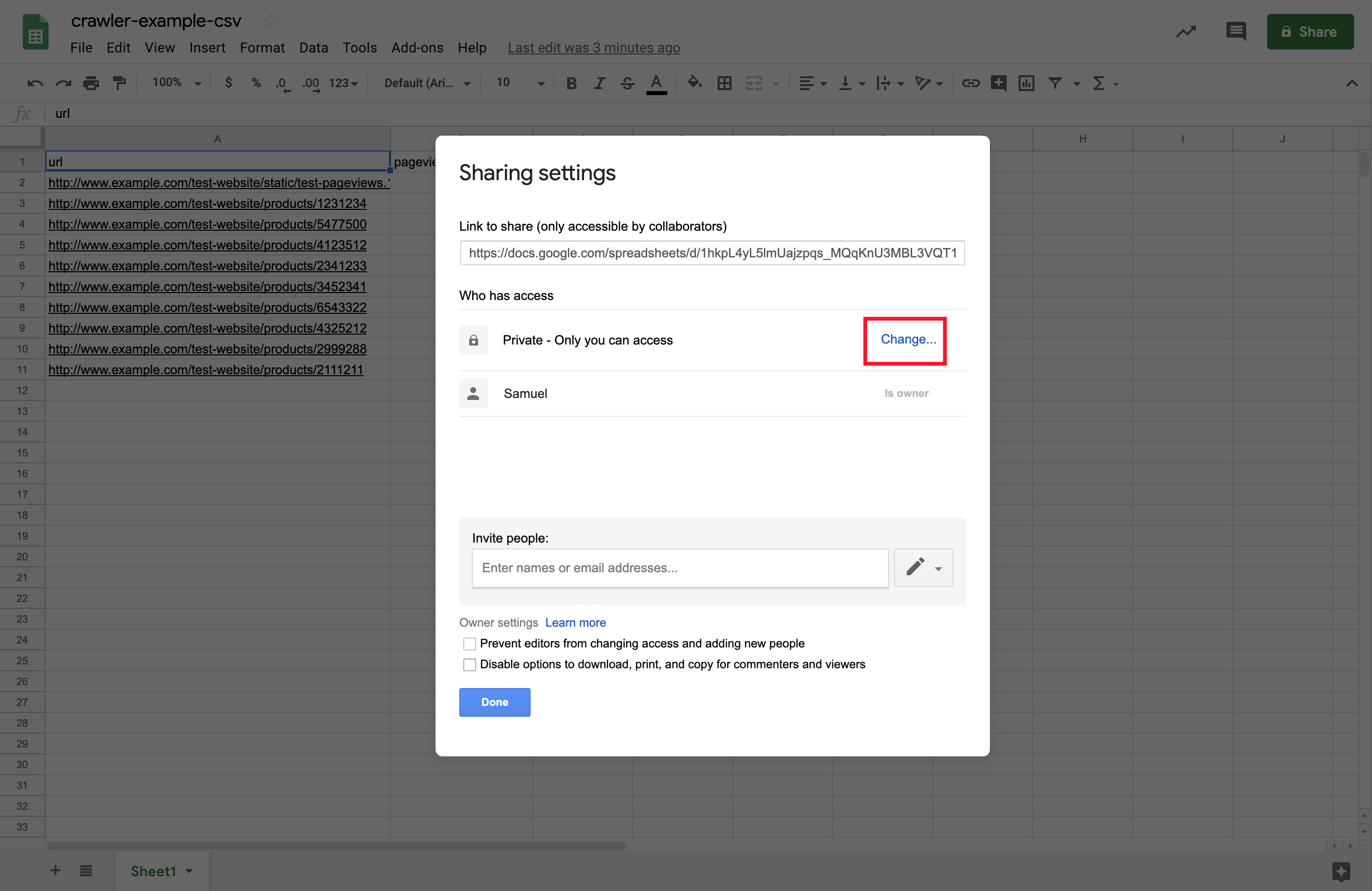
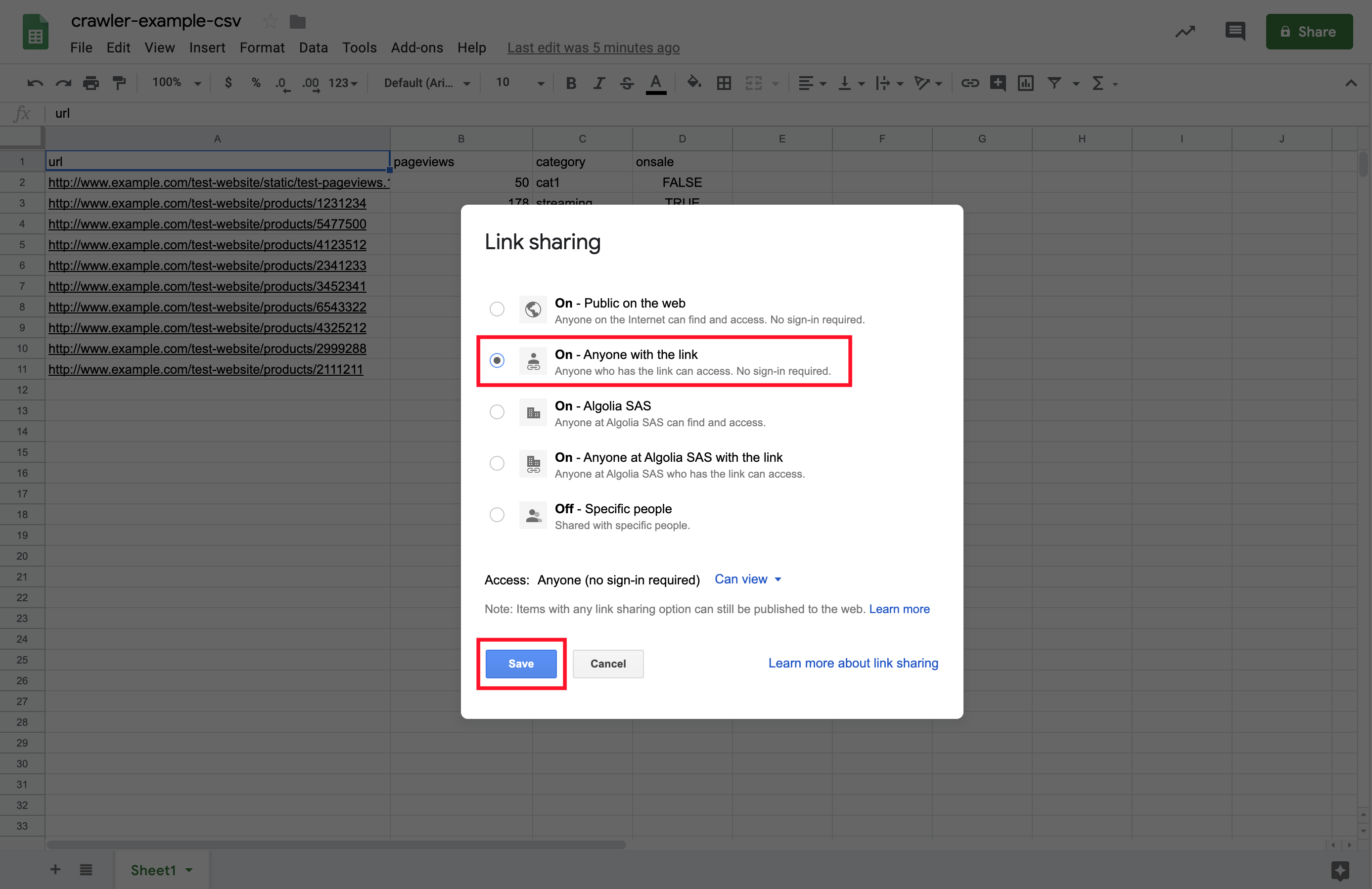
 3. Change the spreadsheet’s Sharing settings so that the file is accessible to anyone who has the sharing link.
3. Change the spreadsheet’s Sharing settings so that the file is accessible to anyone who has the sharing link.
 4. Publish your spreadsheet to the web as a CSV file. To do this, click on the File header, then Publish to the web…
4. Publish your spreadsheet to the web as a CSV file. To do this, click on the File header, then Publish to the web…
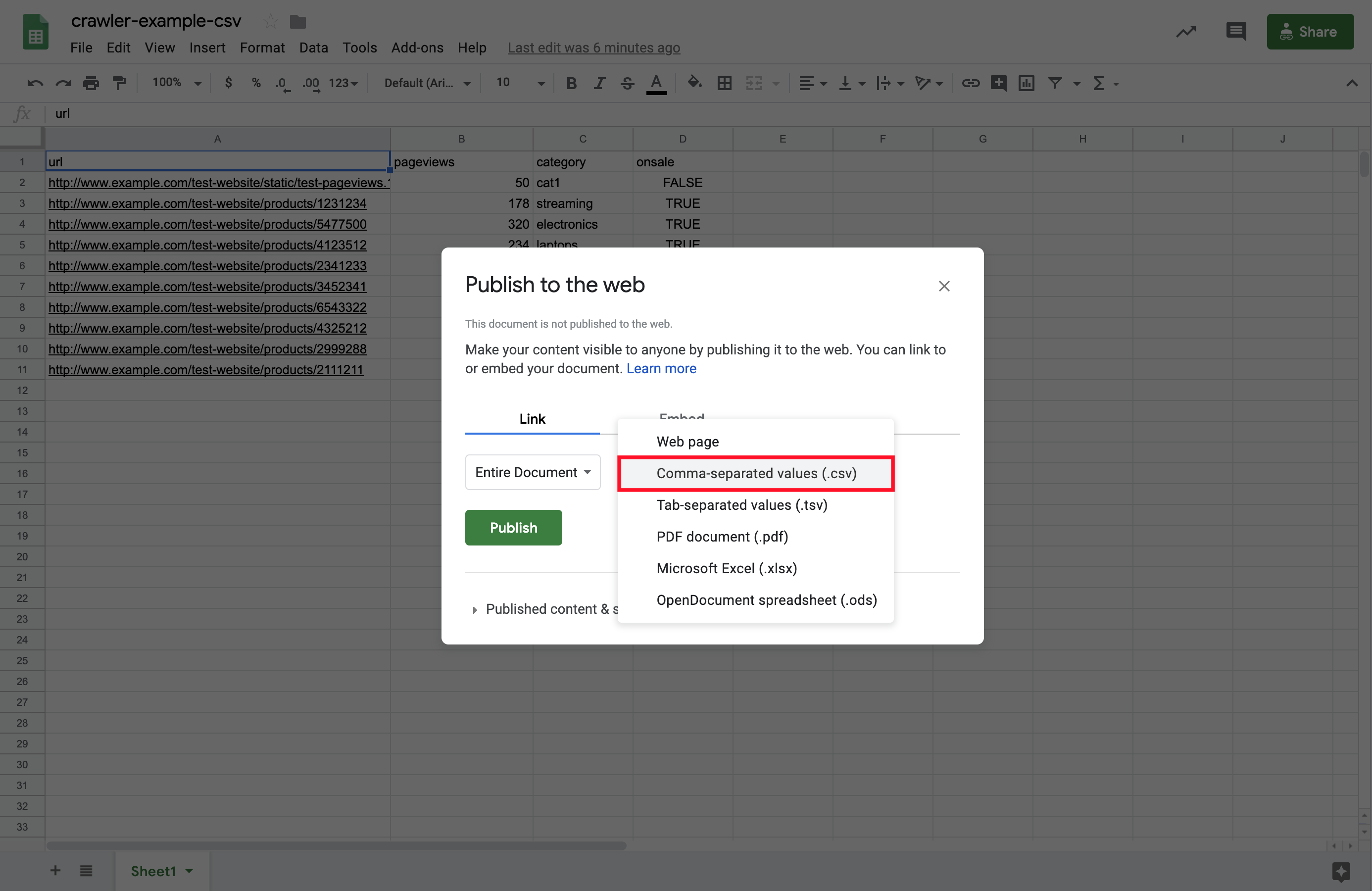
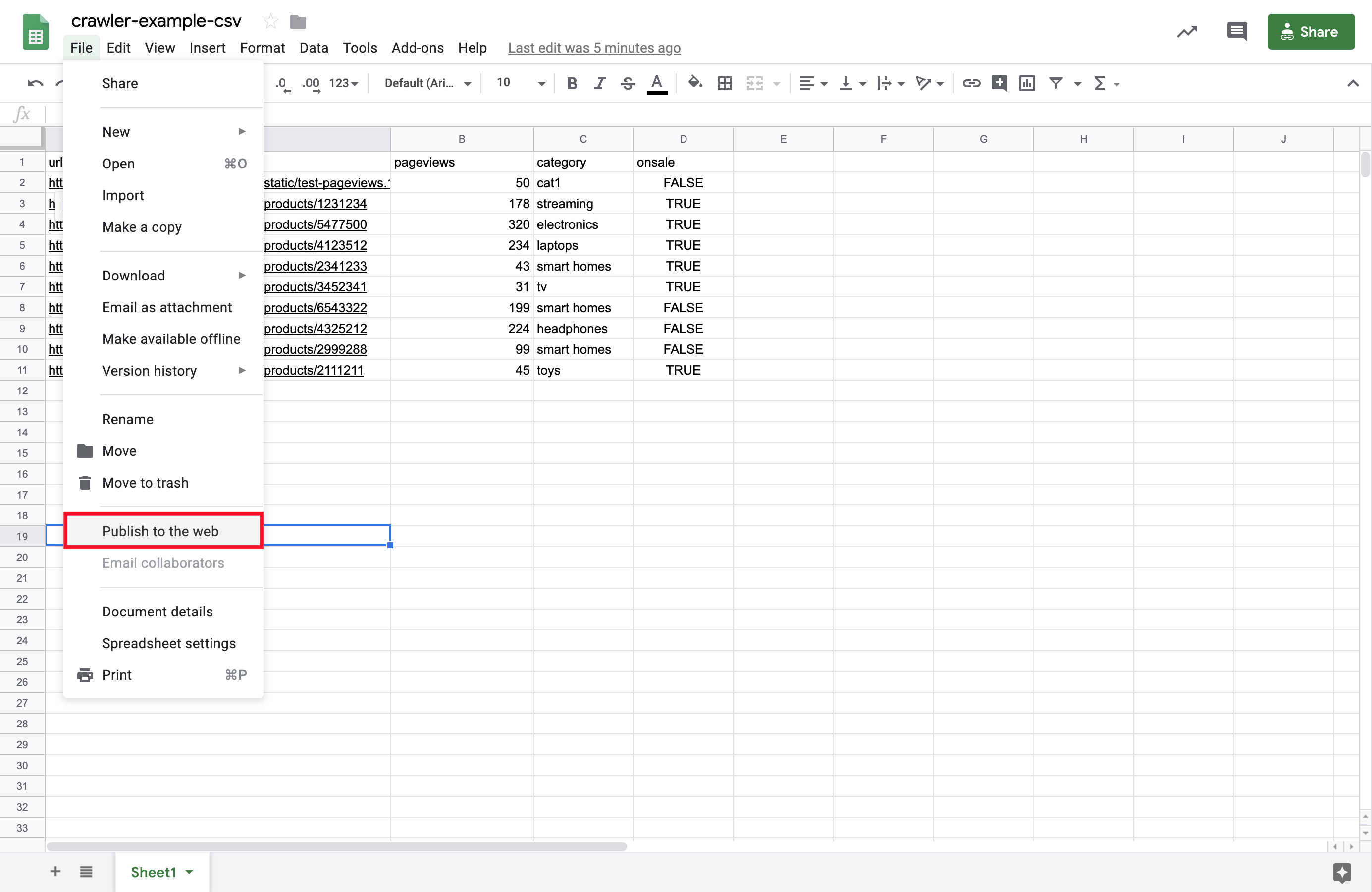 5. Set the link type to Comma-separated values (.csv).
5. Set the link type to Comma-separated values (.csv).
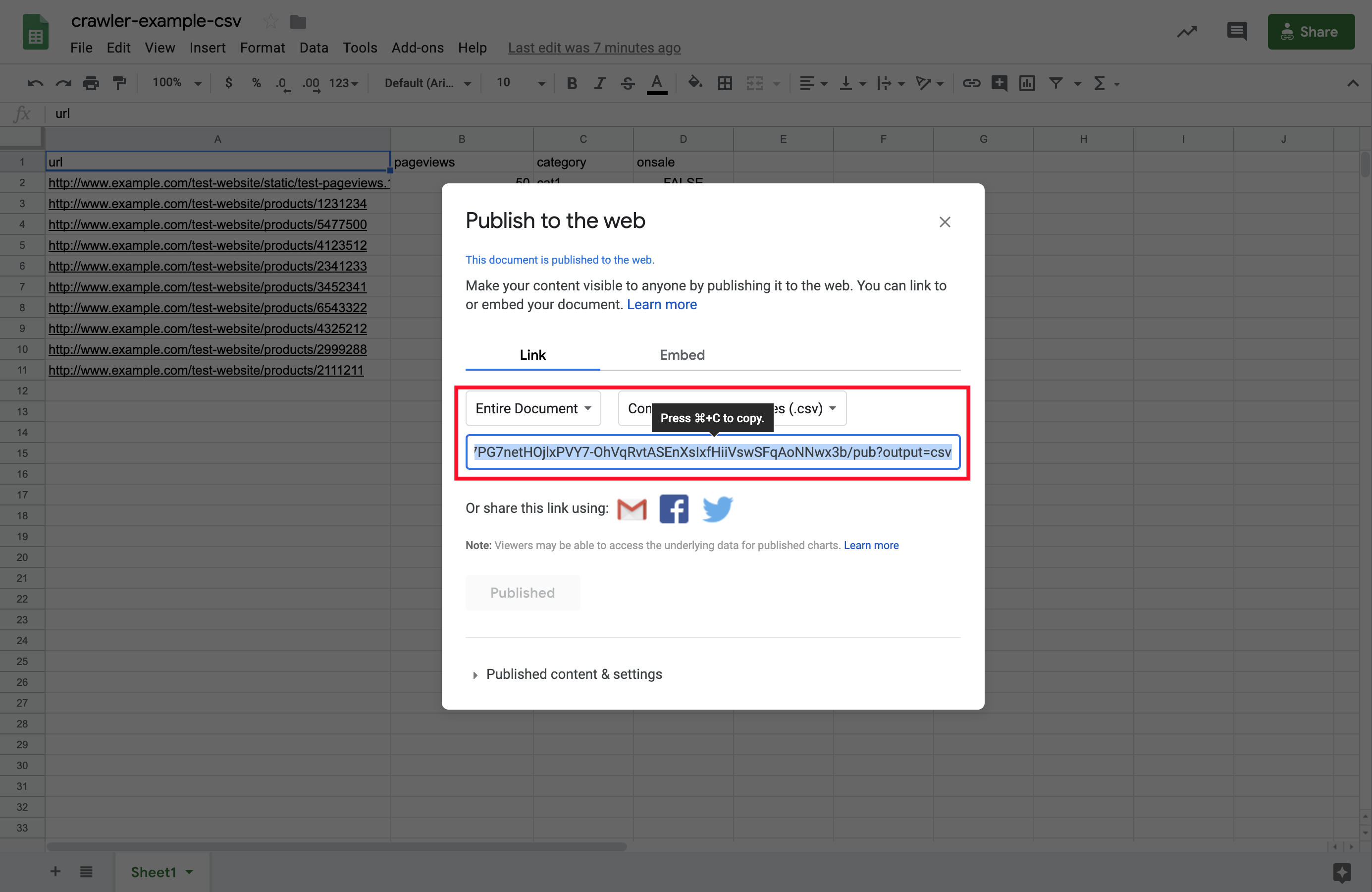
 6. The link generated below is the address that exposes your CSV file.
6. The link generated below is the address that exposes your CSV file.
Enabling automatic updates
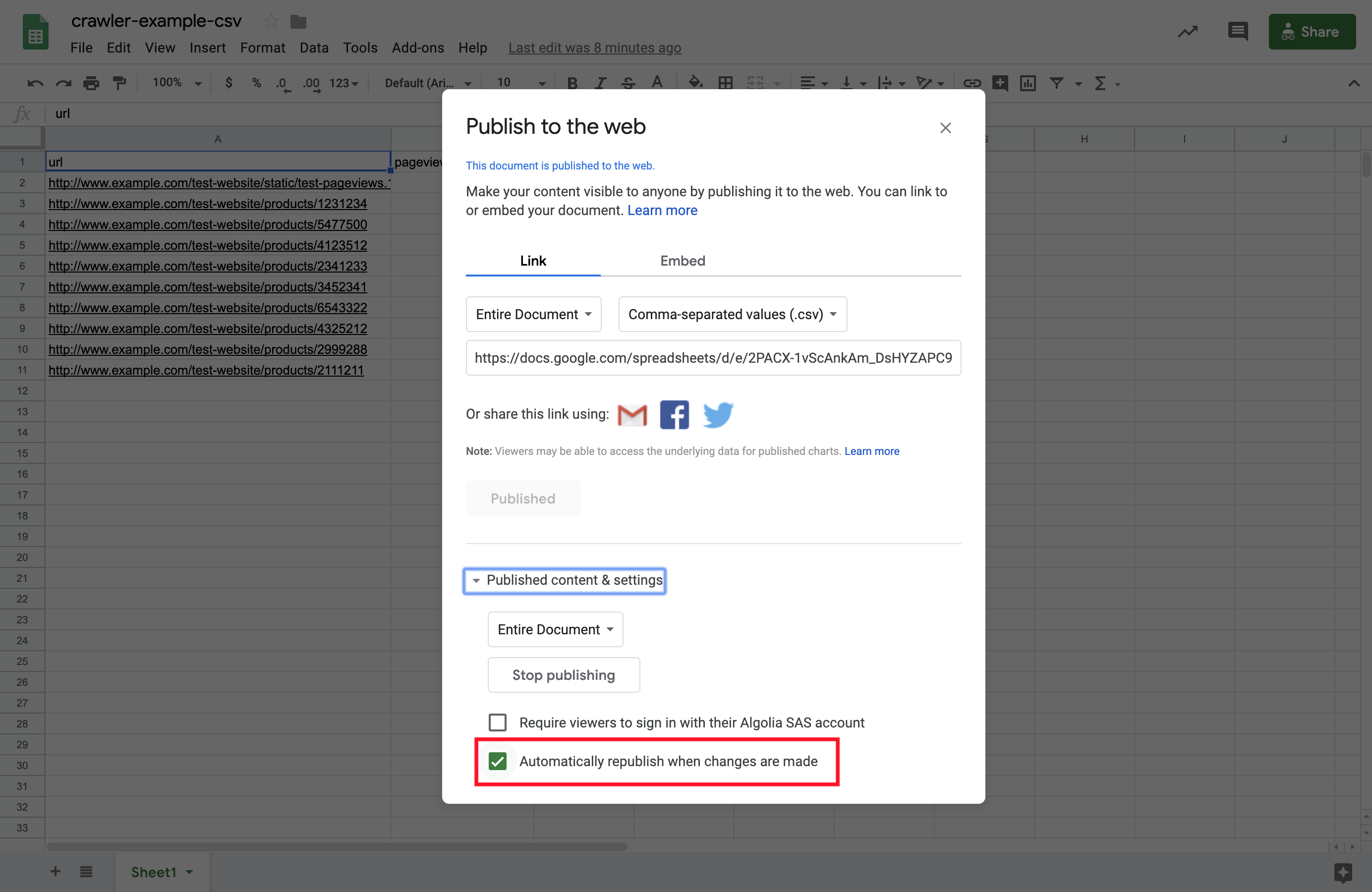
The CSV file is generated with the current data of your Google spreadsheet. By default, all further updates to your spreadsheet change its content.
If you want to disable automatic updating, open the Published Content & settings section and uncheck Automatically republish when changes are made.
Link your published CSV to your crawler’s configuration
In this step, you’ll edit your crawler’s recordExtractor so that it integrates metrics from the published CSV into the crawler produced records.
- Go to your Crawler Admin, select your crawler, and go to the Editor tab.
- Add the
externalDataSourcesparameter to your crawler. You can insert it right above the actions parameter.Copy1 2 3 4 5 6 7
externalDataSources: [ { dataSourceId: 'myCSV', type: 'csv', url: 'https://docs.google.com/spreadsheets/d/e/2PACX-1vScAnkAm_DsHYZAPC9Fiq6zGHxl8h7PG7netHOjlxPVY7-OhVqRvtASEnXsIxfHiiVswSFqAoNNwx3b/pubhtml', }, ]
- You can download external datasets at the beginning of a crawl, or manually. To download them manually, go to the External data tab and click on the Fetch data button. When the operation is done, you should see the data extracted from your published CSV. Note, we only keep data from URLs that match the startUrls or the pathsToMatch properties of your crawler’s configuration.
- Back in the Editor*, with the
dataSourcesparameter of yourrecordExtractor, read values from the external data source you just defined, and store them as attributes for your resulting record.Copy1 2 3 4 5 6 7 8 9
recordExtractor: ({ url, dataSources }) => [ { objectID: url.href, pageviews: dataSources.myCSV.pageviews, category: dataSources.myCSV.category, // There is no boolean type in CSV, so here we convert the string "true" into a boolean onsale: dataSources.myCSV.onsale === 'true', }, ]
- In the Test URL field of the editor, type the URL of one of your pages that has CSV data attached to it.
- Click on Run test.
- You should see the data coming from your CSV in the generated record.
If this doesn’t work as expected, use the External data tab to check that the URL is correctly indexed and verify that it exactly matches the one that has been stored (for example there could be a missing trailing /).
