Indexing Non-HTML Documents
You can use Crawler to index documents such as .pdf’s and .doc’s. Documents are transformed into HTML by a dedicated Tika Server.
Tika
Most documents have complex formats and are not structured as HTML pages.
To allow the crawler to index documents that are formatted differently, we rely on a Tika Server that is maintained by Apache. The server extracts a document’s content and transforms it into a basic HTML file.
Limitations
Because it’s very difficult to translate non-HTML documents into HTML, there are limitations to what can be done:
- A PDF can easily break if it is exported with an unknown font.
- The produced HTML has little semantic value, which will make good relevancy hard to achieve.
- Document indexing is slower than classic HTML indexing.
- Language detection/information is currently not available.
Supported filetypes
Associated extensions: .pdf

For example, given the .pdf file in the image above, the Tika server will expose the following HTML which your crawler then passes to your recordExtractor.
The metadata presented here is not guaranteed to appear on every document.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta name="date" content="2018-07-17T13:35:40Z"/>
<meta name="pdf:PDFVersion" content="1.3"/>
<meta name="pdf:docinfo:title" content="test-docx-file.pages"/>
<meta name="xmp:CreatorTool" content="Pages"/>
<meta name="access_permission:modify_annotations" content="true"/>
<meta name="access_permission:can_print_degraded" content="true"/>
<meta name="dcterms:created" content="2018-07-17T13:35:40Z"/>
<meta name="Last-Modified" content="2018-07-17T13:35:40Z"/>
<meta name="dcterms:modified" content="2018-07-17T13:35:40Z"/>
<meta name="dc:format" content="application/pdf; version=1.3"/>
<meta name="Last-Save-Date" content="2018-07-17T13:35:40Z"/>
<meta name="pdf:docinfo:creator_tool" content="Pages"/>
<meta name="access_permission:fill_in_form" content="true"/>
<meta name="pdf:docinfo:modified" content="2018-07-17T13:35:40Z"/>
<meta name="meta:save-date" content="2018-07-17T13:35:40Z"/>
<meta name="pdf:encrypted" content="false"/>
<meta name="dc:title" content="test-docx-file.pages"/>
<meta name="modified" content="2018-07-17T13:35:40Z"/>
<meta name="Content-Type" content="application/pdf"/>
<meta name="X-Parsed-By" content="org.apache.tika.parser.DefaultParser"/>
<meta name="X-Parsed-By" content="org.apache.tika.parser.pdf.PDFParser"/>
<meta name="meta:creation-date" content="2018-07-17T13:35:40Z"/>
<meta name="created" content="Tue Jul 17 13:35:40 UTC 2018"/>
<meta name="access_permission:extract_for_accessibility" content="true"/>
<meta name="access_permission:assemble_document" content="true"/>
<meta name="xmpTPg:NPages" content="1"/>
<meta name="Creation-Date" content="2018-07-17T13:35:40Z"/>
<meta name="access_permission:extract_content" content="true"/>
<meta name="access_permission:can_print" content="true"/>
<meta name="producer" content="Mac OS X 10.13.5 Quartz PDFContext"/>
<meta name="access_permission:can_modify" content="true"/>
<meta name="pdf:docinfo:producer" content="Mac OS X 10.13.5 Quartz PDFContext"/>
<meta name="pdf:docinfo:created" content="2018-07-17T13:35:40Z"/>
<title>test-docx-file.pages</title>
</head>
<body>
<div class="page">
<p/>
<p>Test PDF file content</p>
<p/>
</div>
</body>
</html>
Doc(x)
Associated extensions: .doc, .docx
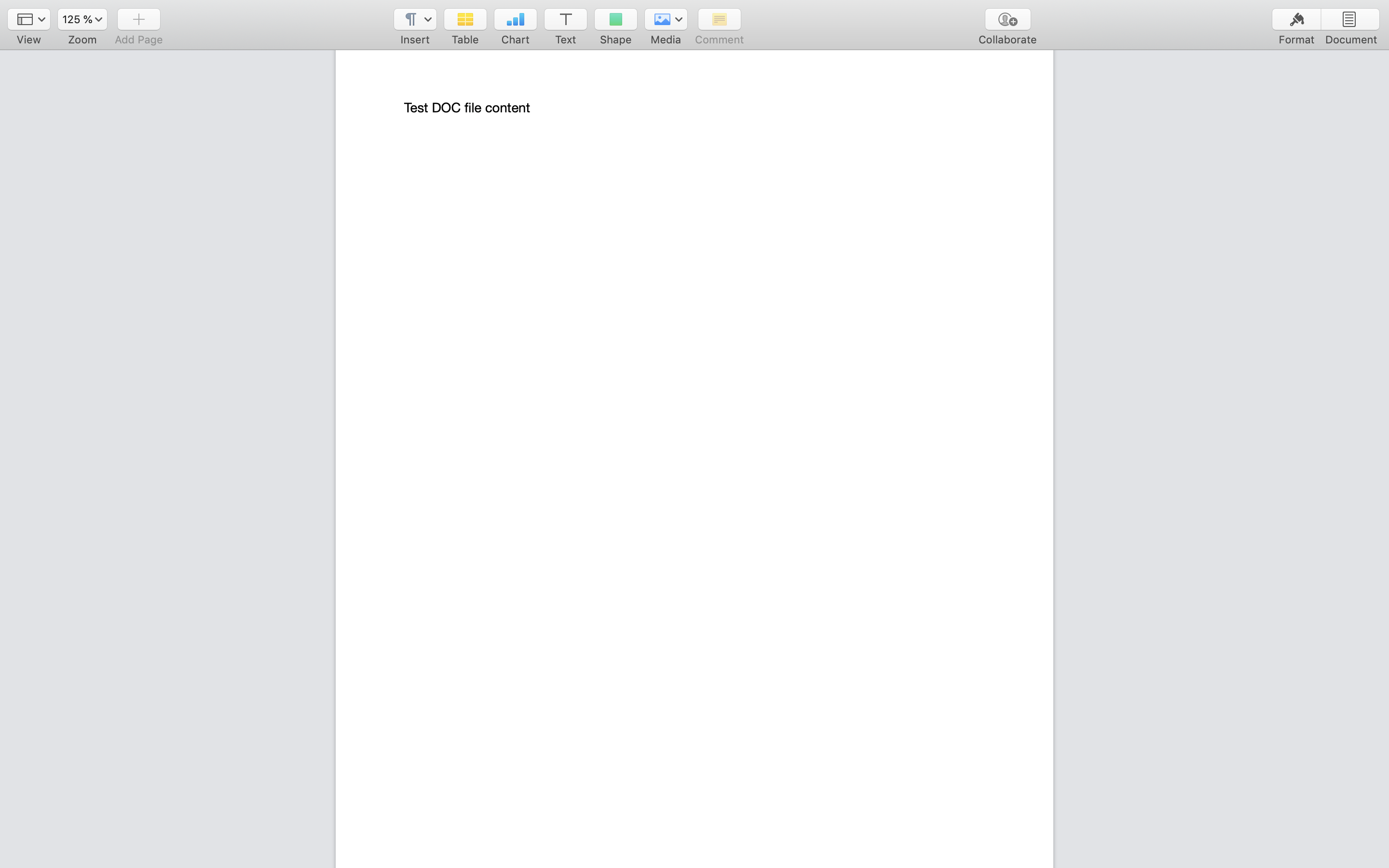
For example, given the .doc file in the image above, the Tika server will expose the following HTML, which your crawler then passes to its recordExtractor.
The metadata presented here is not guaranteed to appear on every document.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta name="X-Parsed-By" content="org.apache.tika.parser.DefaultParser"/>
<meta name="X-Parsed-By" content="org.apache.tika.parser.microsoft.OfficeParser"/>
<meta name="Content-Type" content="application/msword"/>
<title>
</title>
</head>
<body>
<div class="header"/>
<p class="body">Test DOC file content</p>
<div class="footer"/>
</body>
</html>
XLS(X)
Associated extensions: .xls, .xlsx
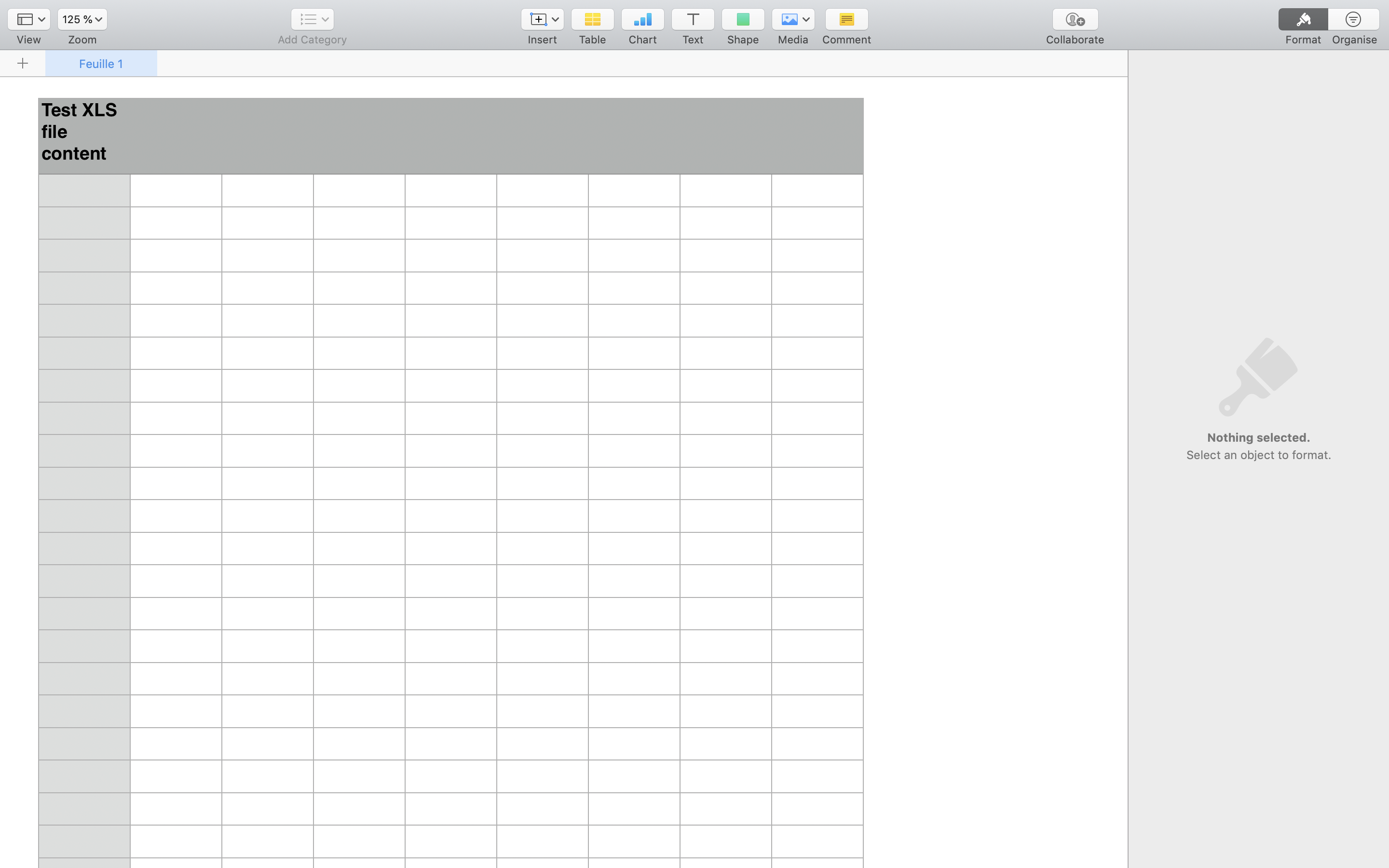
For example, given the .xls file in the image above, the Tika server will expose the following HTML, which your crawler then passes to its recordExtractor.
The metadata presented here is not guaranteed to appear on every document.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta name="X-Parsed-By" content="org.apache.tika.parser.DefaultParser"/>
<meta name="X-Parsed-By" content="org.apache.tika.parser.microsoft.OfficeParser"/>
<meta name="Content-Type" content="application/vnd.ms-excel"/>
<title>
</title>
</head>
<body>
<div class="page">
<h1>Feuille 1</h1>
<table>
<tbody>
<tr>
<td>Test XLS file content</td>
</tr>
</tbody>
</table>
<div class="outside">&C&"Helvetica,Regular"&12&K000000&P</div>
</div>
</body>
</html>
PPT(X)
Associated extensions: .ppt, .pptx

For example, given the .ppt file in the image above, the Tika server will expose the following HTML, which your crawler then passes to its recordExtractor.
The metadata presented here is not guaranteed to appear on every document. {.alert .alert-warning}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta name="X-Parsed-By" content="org.apache.tika.parser.DefaultParser"/>
<meta name="X-Parsed-By" content="org.apache.tika.parser.microsoft.OfficeParser"/>
<meta name="Content-Type" content="application/vnd.ms-powerpoint"/>
<title>
</title>
</head>
<body>
<div class="slideShow">
<div class="slide">
<div class="slide-master-content"/>
<div class="slide-content">
<p>Test PPT file content</p>
<p/>
</div>
</div>
<div class="ocr"/>
</div>
</body>
</html>
Enabling document extraction
To enable document extraction, add the fileTypesToMatch setting to at least one of your crawler’s actions.
When this setting is used and a document is encountered, the parameter $ is assigned the transformed HTML of document. The file’s type is stored in the fileType parameter of your recordExtractor.
1
2
3
4
5
6
7
8
9
10
11
12
13
({
[...]
actions: [
{
indexName: 'crawler-example',
pathsToMatch: ['https://www.example.com/**'],
fileTypesToMatch: ['pdf', 'doc'],
recordExtractor: ({ url, $, fileType }) => {
console.log($.html(), fileType);
}
},
]
});
You can checkout our Github repository of sample crawler configurations for an example of a configuration file that implements document extraction.
