Using the Bayesian Average in Ranking
On this page
Product reviews and ratings play an important role in consumer decision making. Online shoppers look for products with the highest ratings. They often read reviews that give details behind the ratings. In the search and discovery context, businesses consider product reviews to be as relevant as product descriptions. Both are relevant for matching users’ queries.
Algolia’s custom ranking feature enables you to use business signals such as the number of sales and profit margins. You can also use ratings to influence the ranking. For example, when a user types a broad query such as “headphones”, a ratings-based custom ranking ensures that the highest-rated earbuds show up first.
Though this tutorial focuses on star ratings, this solution can work with any product scoring system. For example, you could compute the Bayesian average for the number of up and down votes, or scores based on the number of sells or views.
| Difficulty |
|
The first sections in this guide explain the challenges with star ratings and how the Bayesian average has become the preferred method for ranking by star ratings. If you like, you can jump directly into the coding guide.
The difficulties with calculating a reliable rating
Creating a meaningful ranking strategy based on ratings can be challenging. Is only one rating enough? Or do you need a certain quantity of ratings for the ratings to be reliable? Is a product that receives many mixed ratings, with a range between 1 and 5 (in a 5-star rating system), better than a product with a smaller number of mostly positive ratings? Obviously, a product that receives only 5 stars is a good choice, but is it better than a popular item with hundreds of 4 stars?
A good example is the query “lion” on a movie streaming site. Should the movie “The Lion King” rank above a higher rated but lesser known film like “The Lion in Winter”? Suppose that “The Lion King” has an average of 4.5 stars but “The Lion in Winter” has a higher average of 4.8. If the 4.5 average rating comes from 10,000 ratings and the 4.8 average rating from 100 ratings, which movie should show up first?
The challenge with any rating system—whether for handbags, electronics, or movies—is that the quantity of ratings is as important as the rating itself. Intuitively, the more ratings received, the more confidence you can have in the rating. But again, how many ratings do you need to have confidence that the rating is meaningful?
Comparing different ratings rankings
Consider two ways to rank star ratings:
- Use an arithmetic average that adds together all ratings and divides by the total quantity of ratings. If there are 100 1-star ratings and 10 5-star ratings, the calculation is ((100x1) + (10x5))/ (100+10) = 1.36.
- Use a Bayesian average that adjusts a product’s average rating by how much it varies from the catalog average. This favors products with a higher quantity of ratings.
As already suggested, ignoring the quantity of ratings doesn’t help distinguish between items with 10 ratings and 1000 ratings. You need to at least calculate an average that includes the quantity of ratings.
The following image shows three items ranked by different averages. The left side uses the arithmetic average for ranking. The right side uses the Bayesian average.
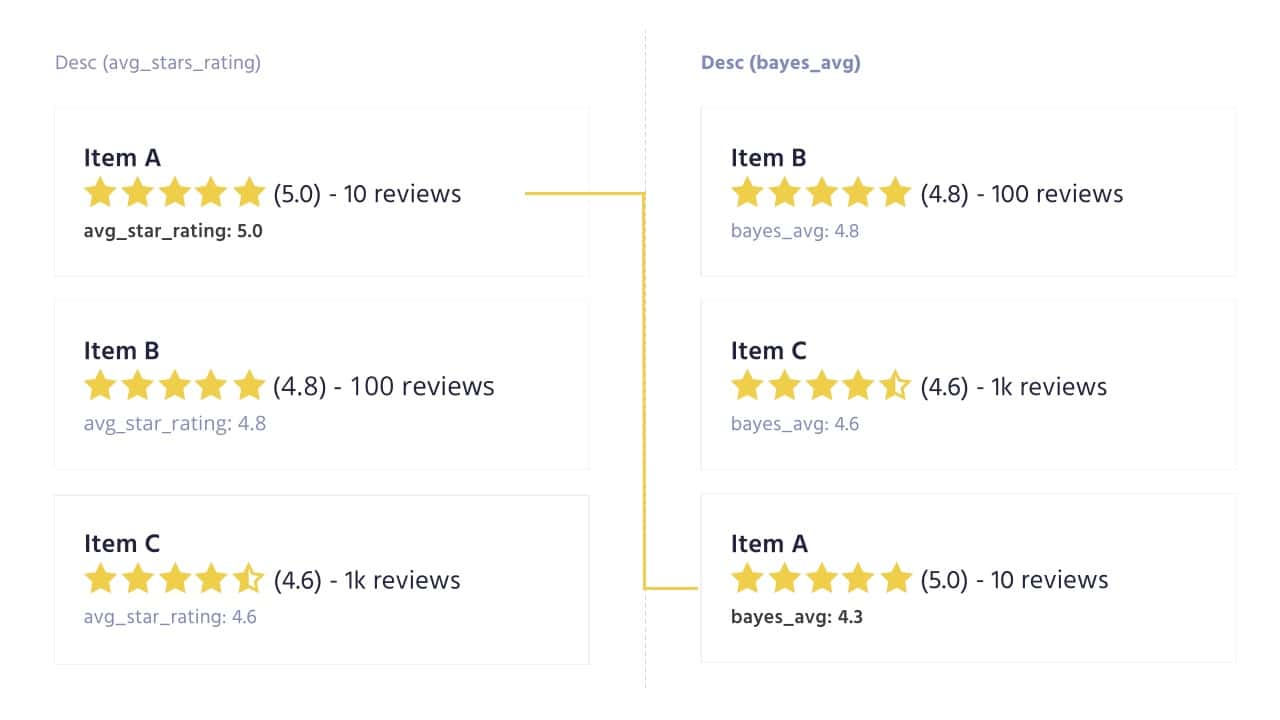
Both sides display the arithmetic average in parenthesis just right of the stars. They also display the average used for ranking as avg_star_rating and bayes_avg respectively, under each item.
By putting Item A at the top, the left side’s ranking is both misleading and unsatisfying. The ranking on the right, based on the Bayesian average, reflects a better balance of rating and quantity of ratings. This example shows how the Bayesian average lowered item A’s average to 4.3 because it measured A’s 10 ratings against B and C’s much larger numbers of ratings. As described later, the Bayesian average left Items B and C unchanged because the Bayesian average only affects items with low rating counts.
In sum, by relativizing ratings in this way, the Bayesian average creates a more reliable comparison between products. It ensures that products with lower numbers of ratings have less weight in the ranking. What follows is a description of the Bayesian average and how to code it.
Understanding the Bayesian average
The Bayesian average adjusts the average rating of products whose rating counts fall below a threshold. Suppose the threshold amount is calculated to be 100. That means average ratings with less than 100 ratings get adjusted, while average ratings with more than 100 ratings don’t change. This threshold amount of 100 is called a confidence number, because it gives you confidence that averages with 100 or more ratings are more reliable than averages with less than 100 ratings.
This confidence number derives from the catalog’s distribution of rating counts and the average rating of all products. By factoring in ratings counts and averages from the whole catalog, the Bayesian average has the following effect on an item’s individual average rating:
- For an item with a fewer than average quantity of ratings, the Bayesian average lowers its artificially high rating by weighing it down (slightly) to the lower catalog average.
- For an item with a lot of ratings (that is, more than the threshold), the Bayesian average doesn’t change its rating average.
How to calculate the Bayesian average
The Bayesian average uses two constants to offset the arithmetic average of an individual product:
- the arithmetic average rating of all products (
m) - a confidence number (
C).
The calculation for m is a straightforward arithmetic average for all products: the sum of all ratings divided by the count of quantity of ratings.
Calculating C requires a bit more math. This tutorial calculates C based on the distribution of the rating counts for each product, where C is equal to the 25% percentile (= the lower quartile). For example, suppose a store has 100 products. To compute C, you take all the products and sort them by the quantity of ratings each has. Some have 10 ratings and others have 100 or 1000 ratings. Once sorted, you find the product at the 25% position on the sorted list and look at how many ratings it has. This is the lower quartile for C. For simplicity, this guide sets C = 100.
Thus, if you calculate the overall average rating (m) of the store’s catalog to be 3.5, the Bayesian average uses both of these values ( m = 3.5 and C = 100) to adjust the arithmetic average. It does this using the following formula:
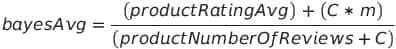
Here’s the same formula with the example numbers plugged in:
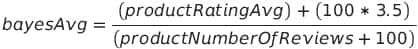
Coding the Bayesian average
This section shows how to code the Bayesian constants (m and C) and the Bayesian average itself. It also discusses when to calculate these values.
Necessary attributes in your index
You need a dataset of products where each product has at least these three attributes:
- The product’s arithmetic average rating (
avg_stars_rating) - The product’s Bayesian average (
bayes_average), this can be empty or0to start - The quantity of ratings (
ratings_count)
Here’s a sample dataset.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
{
"name": "Item A",
"avg_stars_rating": 5,
"bayes_average": 0,
"ratings_count": 10,
},
{
"name": "Item B",
"avg_stars_rating": 4.8,
"bayes_average": 0,
"ratings_count": 100,
},
{
"name": "Item C",
"avg_stars_rating": 4.6,
"bayes_average": 0,
"ratings_count": 1000,
},
This JSON already includes a bayes_average attribute. The purpose of the following code is to calculate the value for bayes_average.
Additionally, the sample dataset doesn’t show other attributes, such as the description of the product, price, item specifications, etc.
Calculating the Bayesian constants
The variables m and C represent the two Bayesian constants. In this code, they’re assigned the values from the preceding section (m = 3.5 and C = 100):
1
2
3
4
// Set the value of the catalog average rating
const m = 3.5; // average rating of all products
// Set the value of the confidence number
const C = 100; // confidence number based on quartile
There are different ways to calculate the C constant. As suggested in the preceding section, you can use a lower quartile % that corresponds to the 25% percentile. You can calculate this value using the following SQL function:
1
2
/* The value C is equal to: */
PERCENTILE_CONT(0.25) WITHIN GROUP ( ORDER BY ratings_count asc) OVER ()
The syntax of this SQL function can differ from one SQL database to another, so you might need to adapt it.
You may also want to calculate separate constants for each product category. This is helpful for use cases with multiple categories of items, like Amazon and other marketplaces.
Calculating the Bayesian average for each product
The variables avg_stars_rating and ratings_count match the attributes in the index that represent, respectively, the rating average and quantity of ratings for each product:
1
2
3
4
// Name of the attribute having the arithmetic average rating per record
const product_ratings_average = 'avg_stars_rating';
// Name of the attribute having the quantity of ratings per record
const product_ratings_count = 'ratings_count';
First, create a function that calculates the Bayesian average. Using all four variables, this function generates the Bayesian average for a single product:
1
2
3
const bayesianAverage = (product_ratings_count, product_ratings_average, m, C) => {
return (product_ratings_count*product_ratings_average + m*C) / (product_ratings_count+C)
}
Next, perform the calculations for every product. You can do this by:
- retrieving every product in the index, using the
browsemethod. - running them through the preceding Bayesian average function to calculate their Bayesian average
- updating the index with their new values
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// retrieve every product in the index
var browser = index.browseAll();
// go through the records and calculate the Bayesian average
browser.on('result', function onResult(content) {
hits = hits.concat(content.hits);
const decorated_hits = _.map(hits, hit => ({ ...hit, bayes_average: bayesianAverage(
hit[product_ratings_count], hit[product_ratings_average], m, C
)}))
// update every product with its newly calculated Bayesian average
index.saveObjects(decorated_hits, function(err, content) {
if (err) throw err;
console.log("Updated batch of 1000 records")
});
});
The full example looks like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
var algoliasearch = require('algoliasearch');
var hits = [];
var _ = require('lodash');
// Set your unique credentials and index name here
var client = algoliasearch('<YOUR APP ID HERE>', '<YOUR API KEY HERE>');
var index = client.initIndex('<YOUR INDEX HERE>');
var browser = index.browseAll();
// Name of the attribute having the arithmetic average rating per record
const product_ratings_average = 'avg_stars_rating';
// Name of the attribute having the quantity of ratings per record
const product_ratings_count = 'ratings_count';
// Set the value of the prior to be used
const m = 3;
// Set the value of the confidence to be used
const C = 25;
// END of configuration
const bayesianAverage = (product_ratings_count, product_ratings_average, m, C) => {
return (product_ratings_count*product_ratings_average + m*C) / (product_ratings_count+C)
}
// Use the browse method to retrieve all hits and update them with their Bayesian average
browser.on('result', function onResult(content) {
hits = hits.concat(content.hits);
const decorated_hits = _.map(hits, hit => ({ ...hit, bayesian_average: bayesianAverage(
hit[product_ratings_count], hit[product_ratings_average], m, C
)}))
index.saveObjects(decorated_hits, function(err, content) {
if (err) throw err;
console.log("Updated batch of 1000 records")
});
});
browser.on('end', function onEnd() {
console.log('We got %d hits', hits.length);
});
browser.on('error', function onError(err) {
throw err;
});
Frequency and methods of updating the Bayesian average
As users rate products, their Bayesian average changes—but not necessarily with every new rating. Here’s some guidance on how often to update the Bayesian average.
For calculating the Bayesian constants (m and C), you can create a batch job that runs once a week or month. These constants don’t need to change that often.
It’s important to store these constants so that you can calculate all products based on the same constants. Thus, whenever you change these constants, you should recalculate every product’s Bayesian average.
For calculating the Bayesian average for one or more products, you can recalculate the Bayesian average periodically during the day, every night, or even weekly. It all depends on how many ratings you get on a daily basis. For example, Uber might want to update their drivers’ averages several times a day, whereas Amazon might be fine with an overnight process, or even weekly. Essentially, the more often people rate your products, the more often you should update the Bayesian average.
Because the Bayesian calculation is an average, the values don’t change with every new rating. Thus, it’s usually not necessary to recalculate with every new rating. You can recalculate Bayesian averages whenever you update your product index. Note that because the Bayesian average affects one attribute per record, you can do a partial update to change only the Bayesian average attribute.
Incorporating the Bayesian average as a custom ranking
As you’ve seen, you add the Bayesian average attribute to every product. It’s used as a custom ranking attribute to rank records by ratings. There are several considerations when using the Bayesian average as a custom ranking. For example:
- You can use it as a single custom ranking or combine it with other custom ranking attributes.
- Sometimes it’s better to group together items with similar Bayesian averages.
- You can add more factors to the Bayesian calculation to improve its accuracy.
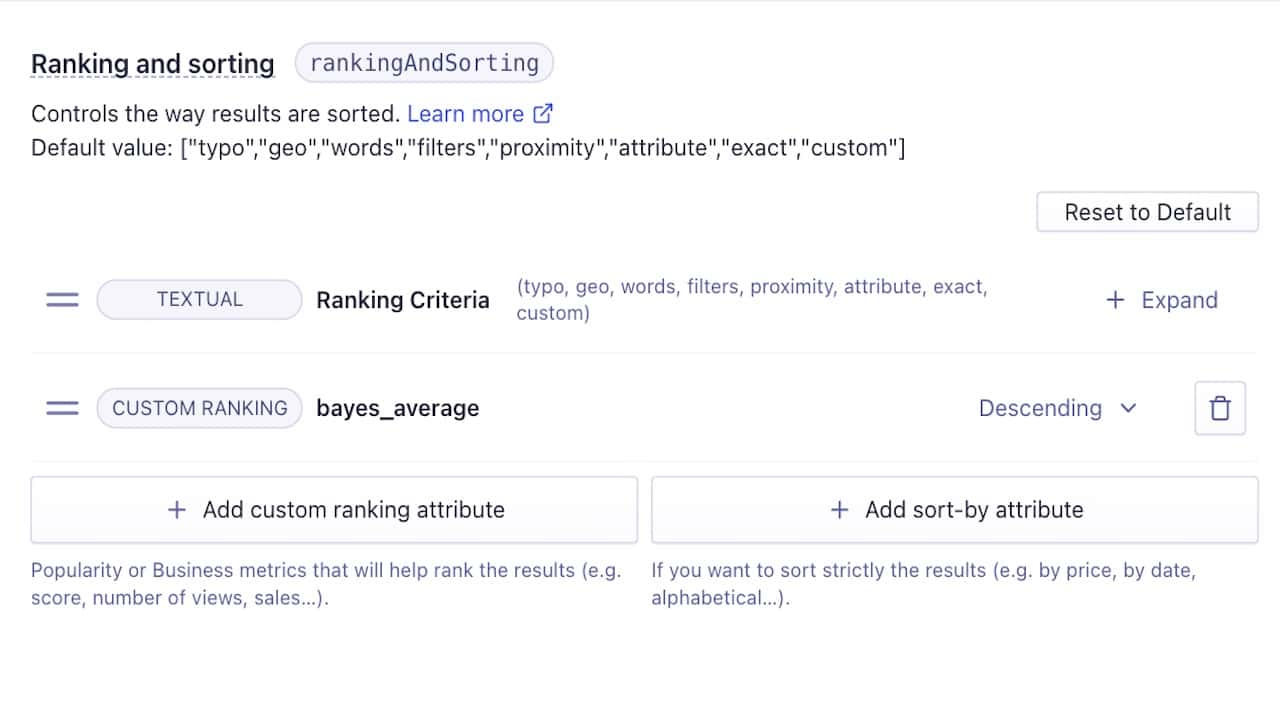
Using the Bayesian average as a single custom ranking
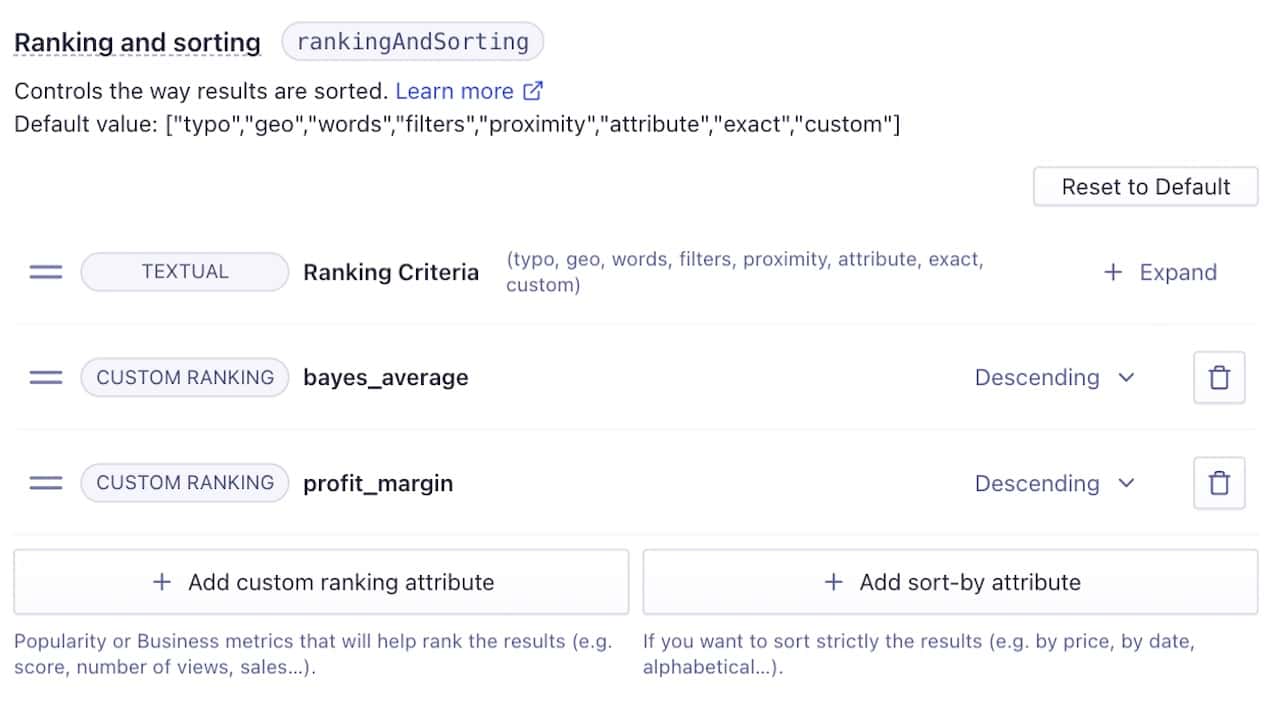
Up to this point, the assumption is that the Bayesian average operates alone in ranking your results. In that case, you can use the new bayes_average attribute you’ve added in each of your records as a custom ranking value, as seen in the following image:
Mixing the Bayesian average with other custom ranking signals
More often, you want to add a second ranking criteria as a tie-breaker, to handle cases where two or more results have the same Bayesian average. In these cases, you can use typical business metrics, such as most sales, views, margins, or anything else.
For example, if you have ten records with a Bayesian average of 4, you need a second custom ranking to break the tie between these 4’s. Here’s an example where a product’s profit_margin acts as a secondary tie-breaker for the primary Bayesian average ranking:
Rounding and grouping scores
You may want to round your scores to one of the 5 ratings (1, 2, 3, 4, or 5), or more granularly (0.5, 1, 1.5, …, 5), by using a rounding function. This avoids impacting the ranking with insignificant differences between products. For example, you may decide that products with the Bayesian averages of 3.15 and 3.16 should have the same ranking.
You can also group ratings. For example, you can put products with a Bayesian average between 3.8 and 4.2 into one group with a rating of 4, products with averages between 4.3 and 4.7 into another group with rating 4.5, and so forth.
Not every group needs to have the same range. For example, one group can contain ratings between 1 and 2, whereas another group can contain ratings between 3 and 3.5, etc. This is helpful when your product ratings are unevenly distributed, for example, many more 3’s than 1’s. Grouping is another name for bucketing, which not only removes insignificant differences between products, but tailors the grouping to your precise business needs or dataset.
Adding multiple indicators to the Bayesian average calculation
While using Bayesian averages is an excellent way to rank results, it might be too simplistic depending on the size or nature of your business. Some businesses change the way they compute an “average star rating.”
For example, they may incorporate other signals into their average, such as weighing reviews from validated reviewers differently, or excluding reviews that have less than five likes, or removing high and low ratings that deviate too much from the average (assuming your ratings follow a bell curve, which most do.)
In sum, whether it be with rounding, grouping, or using multiple indicators, you’re improving upon the already more reliable Bayesian average, thereby creating an even more reliable indicator of favorite products.
Next steps and resources
Feel free to share other methods you’ve used to assess the level of enthusiasm for your individual products. Contact your dedicated Solutions Engineer or post your ideas on Algolia’s community forum.

